第一章 树莓派5部署yolov5-lite
版本信息
更新日期:2025.9.19
版本:V1.2
文件总览
-
YOLOv5-Lite文件包提取码: rxrx
autostart
└─ run.desktop
takepic
├─ takepic.py
└─ images
└─ images_1.jpg
-
yolov5-lite(train)提取码: rxrx
-
YOLOv5-Lite(custom_model)文件包提取码: rxrx
环境搭建
实验平台:幻思创新FanciSwarm® 树莓派5 无人机
树莓派5附带的SD卡本身就带有树莓派5最新版本系统。如需重新刷写操作系统,请参考树莓派系统环境烧录指南(点击查看)。
- 系统启动后,首先需要开启SSH和串口模块
左上角树莓派图标-->首选项-->树莓派配置-->接口
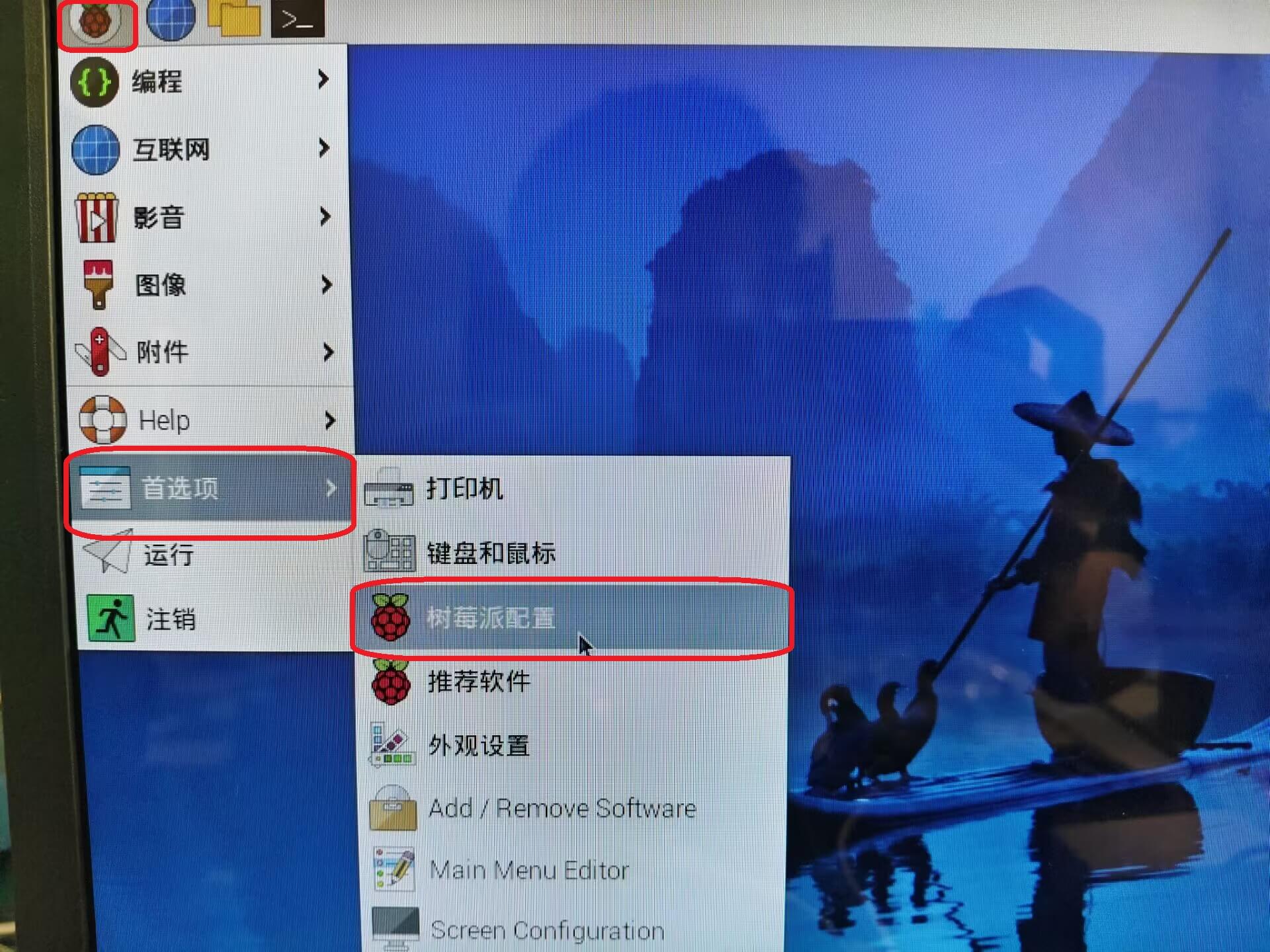
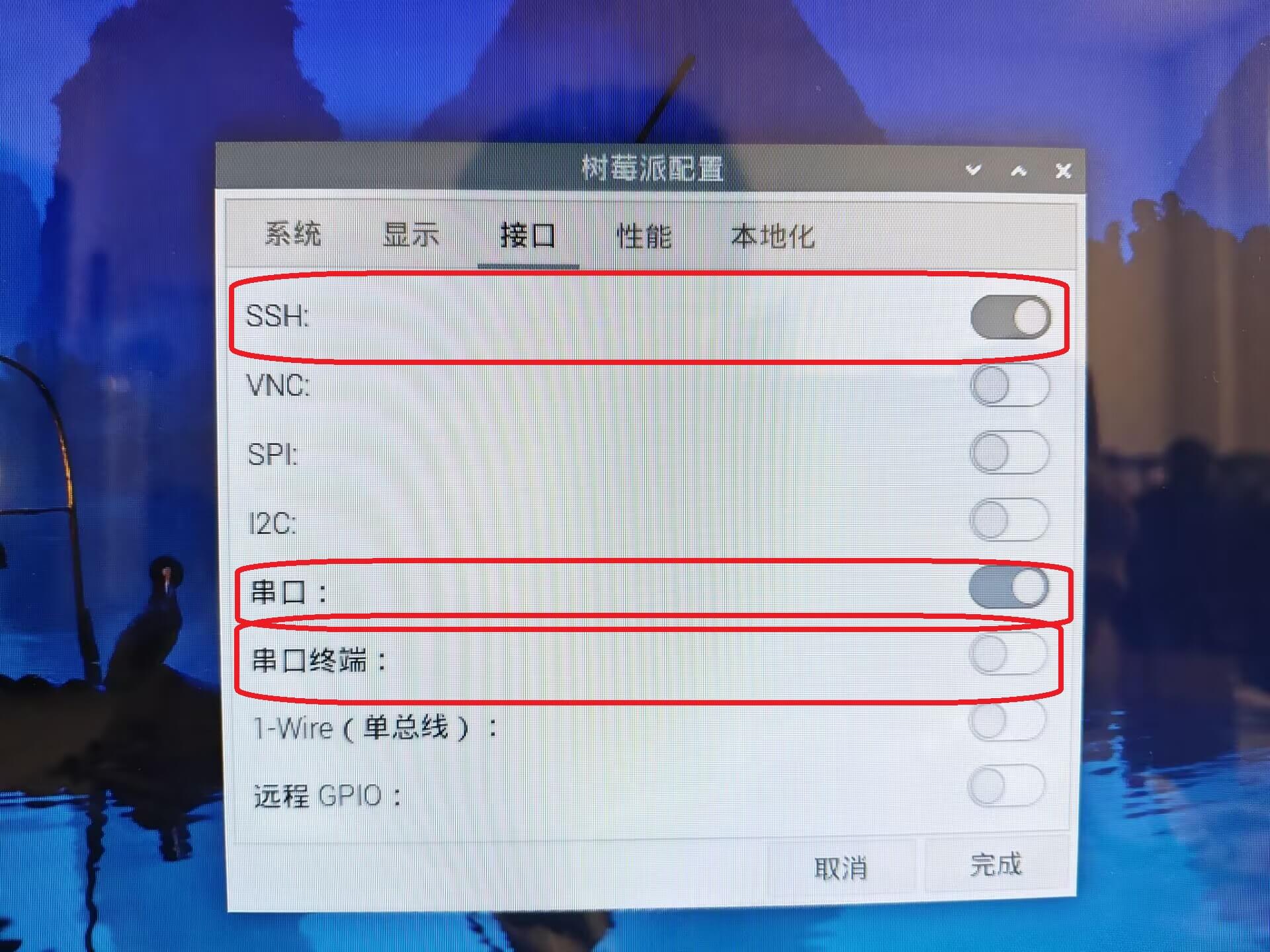
打开SSH和串口,关闭串口终端,重启
2. 配置CSI摄像头
首先更新软件包
sudo apt update
sudo apt-get update
sudo apt upgrade -y
sudo apt-get upgrade -y
编辑config.txt
sudo nano /boot/firmware/config.txt
找到camera_auto_detect=1这一行,将其修改为camera_auto_detect=0,以禁用自动检测功能。然后,根据您的摄像头型号添加相应的dtoverlay配置。例如,如果我们使用的是IMX219摄像头,添加以下行:
dtoverlay=imx219,cam0
保存并退出编辑器(在nano中按CTRL+O,然后按Enter,最后按CTRL+X退出)。配置完成后,重启您的树莓派:
sudo reboot
- 系统环境配置好之后我们就需要去配置python环境,首先更新以下系统源。
sudo apt update
sudo apt-get update
sudo apt upgrade -y
sudo apt-get upgrade -y
之后我们安装树莓派驱动CSI摄像头的python包
sudo apt install python3-libcamera python3-picamera2 -y
安装好之后使用下面命令进行测试
python -c "import libcamera; print('libcamera imported successfully')"
现在就可以直接把我们提供的YOLOv5-Lite文件包(注意,不是custom_model版本)放在home目录下面,然后进入YOLOv5-Lite目录
接下来我们创建虚拟环境,--system-site-packages可以将系统中的python包一并加入虚拟环境。
python3 -m venv venv-yolo --system-site-packages
激活虚拟环境
source ./venv-yolo/bin/activate
安装依赖包
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install opencv-python==4.6.0.66
pip install numpy==1.25.2
环境装好之后我们先测试一下能否正常运行
python detect.py
最后我们进行开机自启动配置,将教程提供的autostart文件夹放到/home/pi/.config/目录下面就可以了,重新启动一下插上显示屏观察效果。
sudo reboot
训练集准备以及划分
实验平台:使用个人PC的windows环境划分数据集
我们在自己训练模型的时候,准备训练集是很重要的一步,直接决定了训练出模型的好坏。
如果要自己拍照准备数据集,我们建议使用树莓派的CSI摄像头采集画面,这样训练模型的画面参数和真正运行时候的画面参数才是一样的。
使用我们提供的CSI摄像头(imx219摄像头)拍照程序takepic.py进行图像采集
虚拟环境和yolov5-lite一致,所以要先source一下虚拟环境再去启动python文件
source ./YOLOv5-Lite/venv-yolo/bin/activate
cd ./takepic
python ./takepic.py
启动程序之后按键盘“s”键拍摄照片,照片保存路径在takepic.py文件13行,如有需要自行更改,注意如果使用相对路径的话是按照终端的路径进行相对,如果终端路径下没有images文件夹请自行建立。
output_dir = "./images"
采集过照片之后使用labelimg进行标注
- 打开Labelimg程序首先转换数据集格式为YOLO

- 然后设置自动保存
- 最后打开图片目录和更改标签存放目录
- 等到所有图片都标注完毕,即可退出程序

- Labelimg快捷键
- “w” -- 框选
- "a" -- 上一张图片
- "d" -- 下一张图片
准备好训练集之后再使用我们提供的划分训练集python脚本,注意要自己更改图片和label路径
使用我们给的huafen.py去划分数据集,文件第5行可以根据自己要求修改train,val的比例。
def split_dataset(image_folder, txt_folder, output_images_path, output_labels_path, split_ratio=(0.7, 0.3)):
使用前请自行更改路径变量
image_folder_path = "D:\Data\images_ready2train\images"
txt_folder_path = "D:\Data\images_ready2train\labels"
output_images_path = "D:\Data\images_ready2train\datasets\images"
output_labels_path = "D:\Data\images_ready2train\datasets\labels"
模型训练以及部署
实验平台:使用个人PC的windows环境连接阿里云的云算力平台
为了统一模型的运行环境和训练环境,我们这次使用阿里云魔塔社区提供的免费云算力平台训练自己的模型
我们百度搜索魔塔社区,注册账号并绑定阿里云账号。
完成了上述步骤之后我们进入到魔塔社区的notebook界面
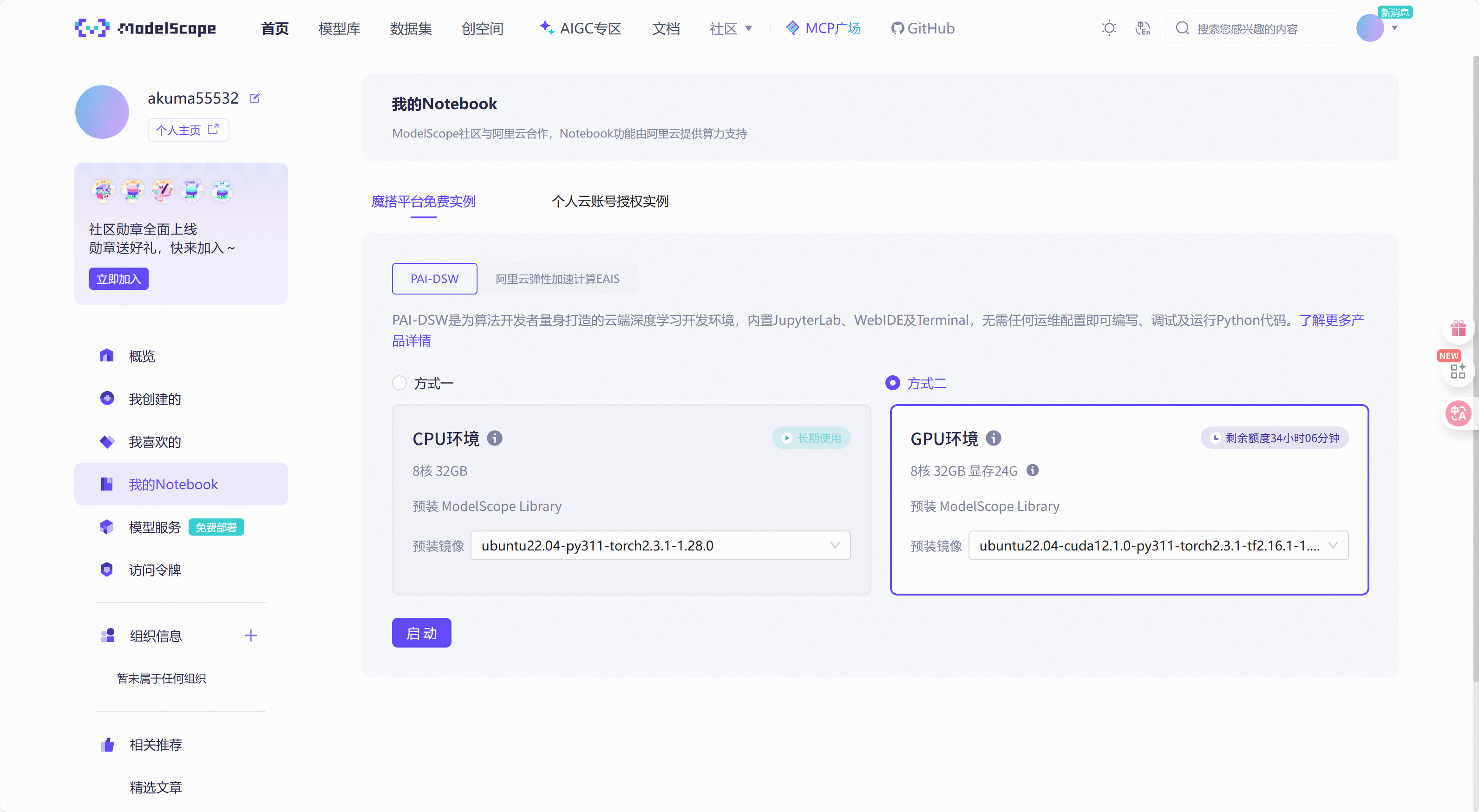
选择GPU环境,可以看到社区给我们提供了每周35个小时的使用,这已经足够我们学习和训练(训练集不过于庞大),启动之后就直接点击"查看Notebook"进入云算力平台。
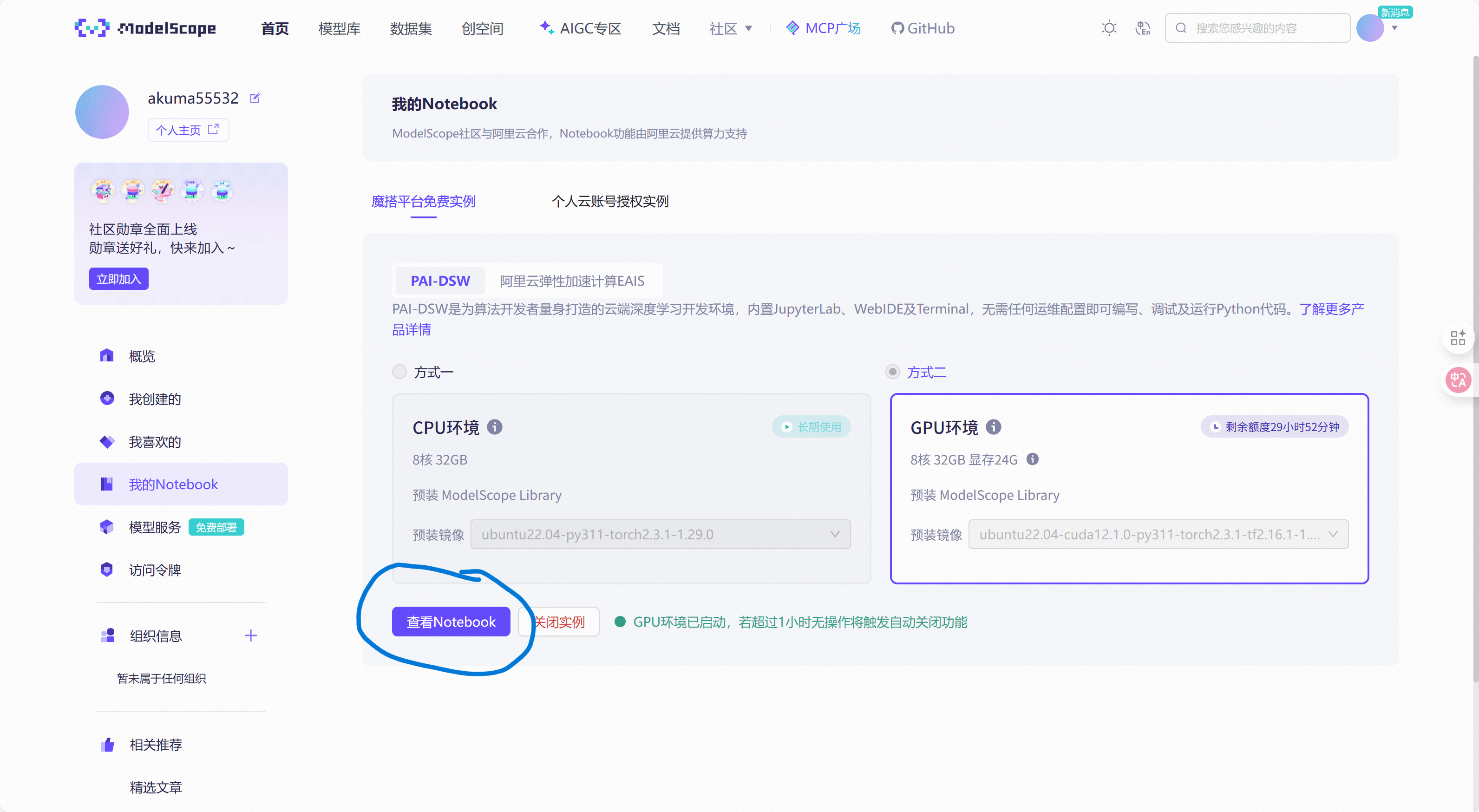
接着点击terminal就可以在终端输入指令来进行操作
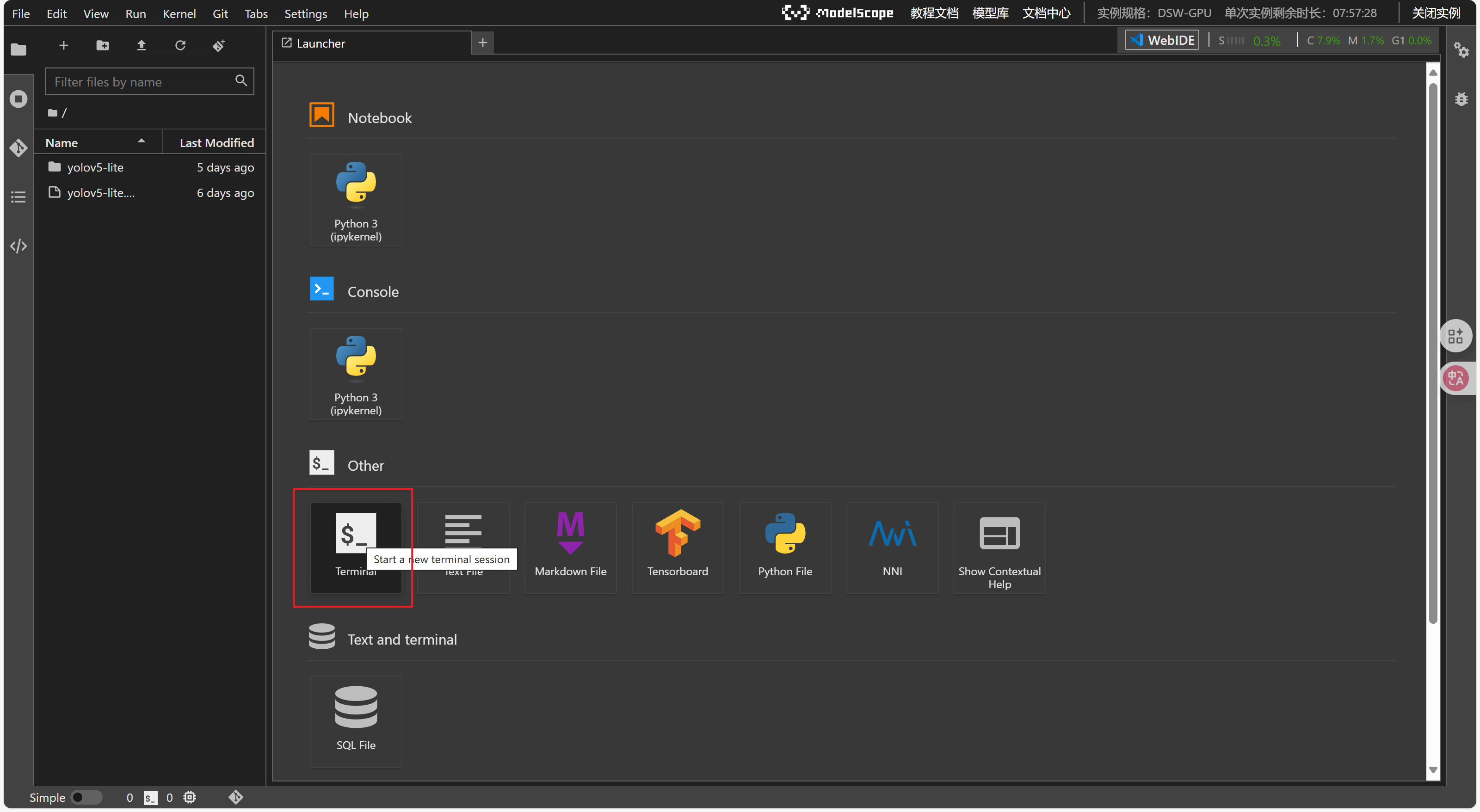
将我们提供的yolov5-lite(train)文件包拖拽上传到workspace根目录下面
解压缩
unzip ./yolov5-lite -d ./yolov5-lite
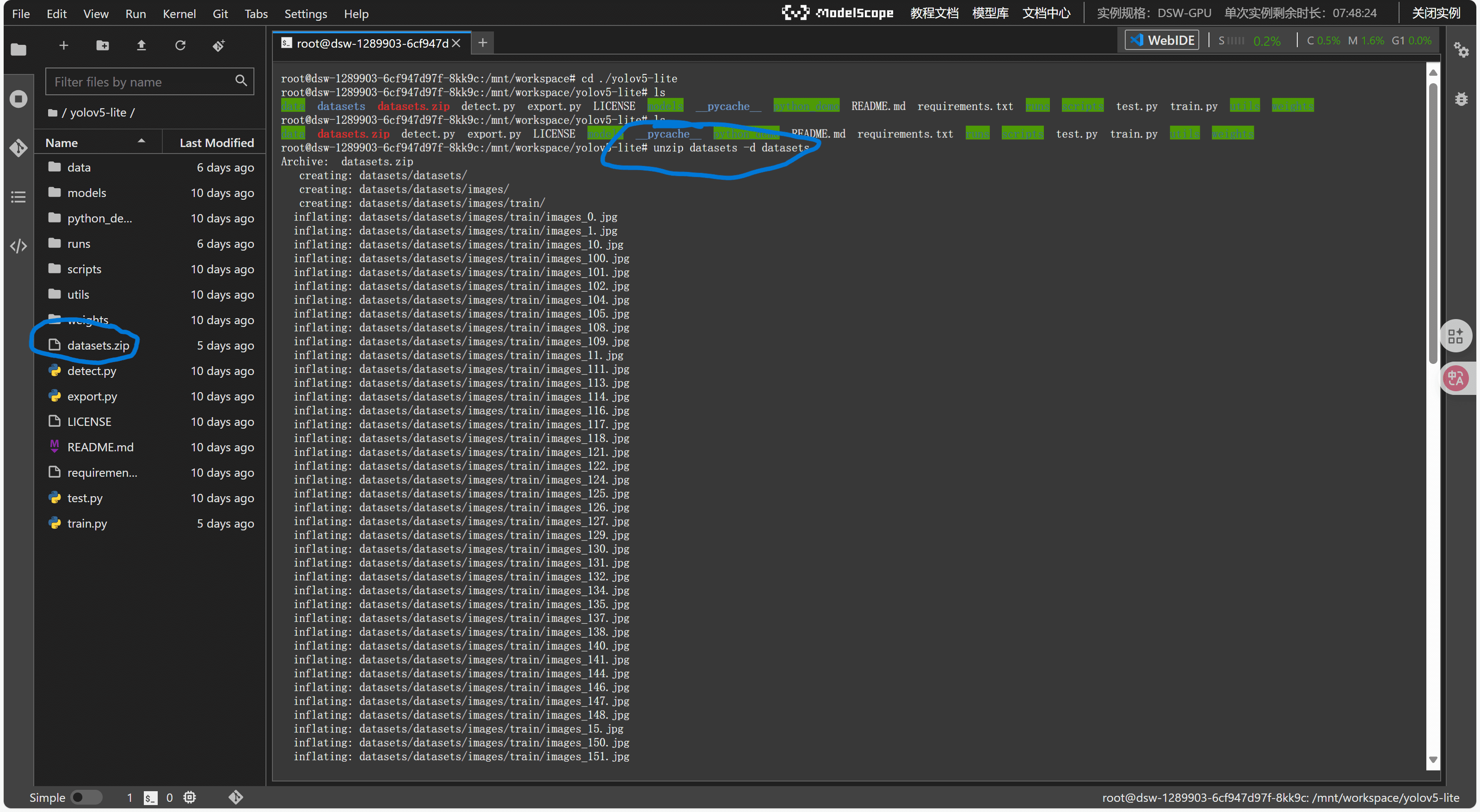
还需要上传自己的数据集并编写数据集文件(格式如下)
train: ./datasets/images/train
val: ./datasets/images/val
nc: 1
names: [ "drone" ]
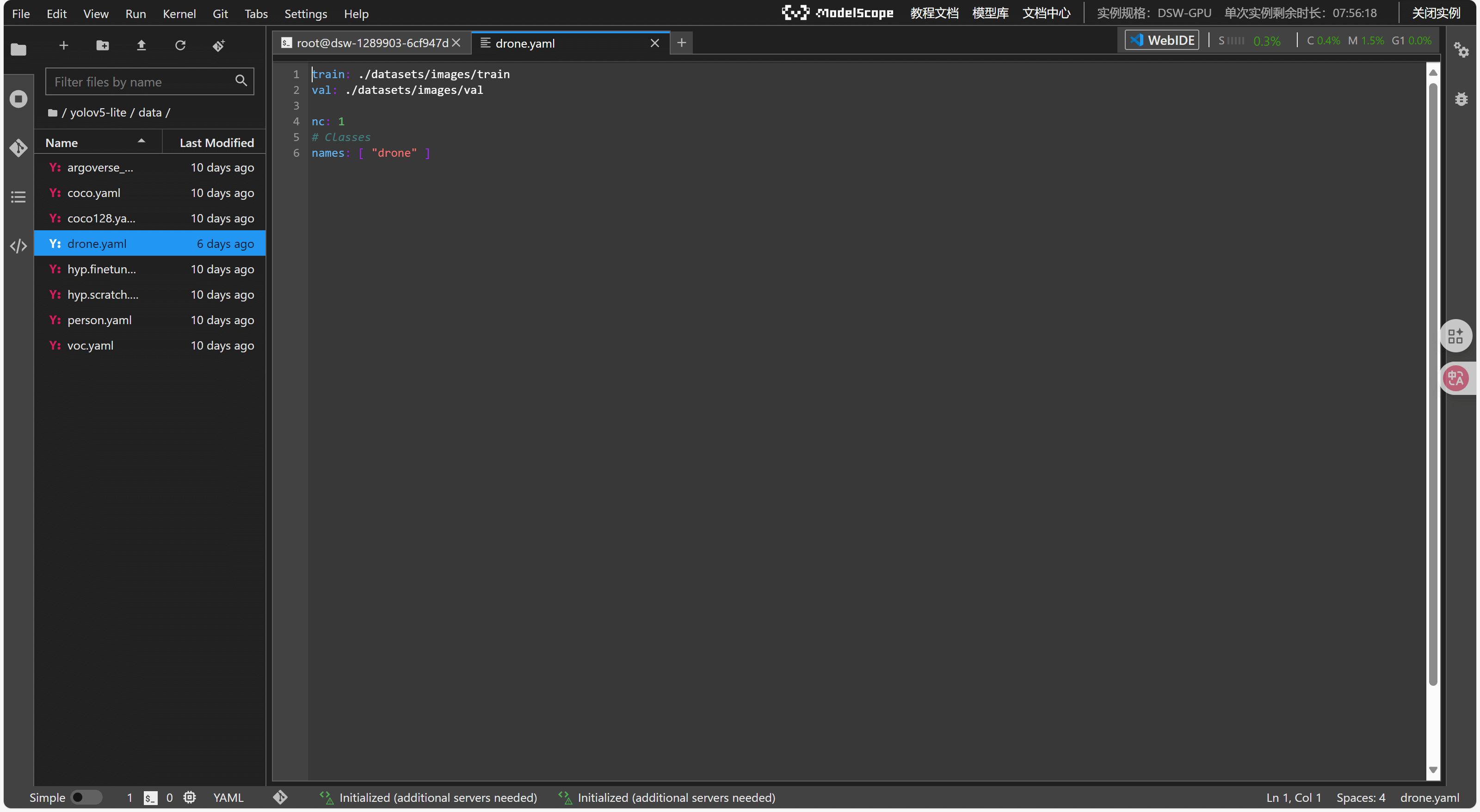
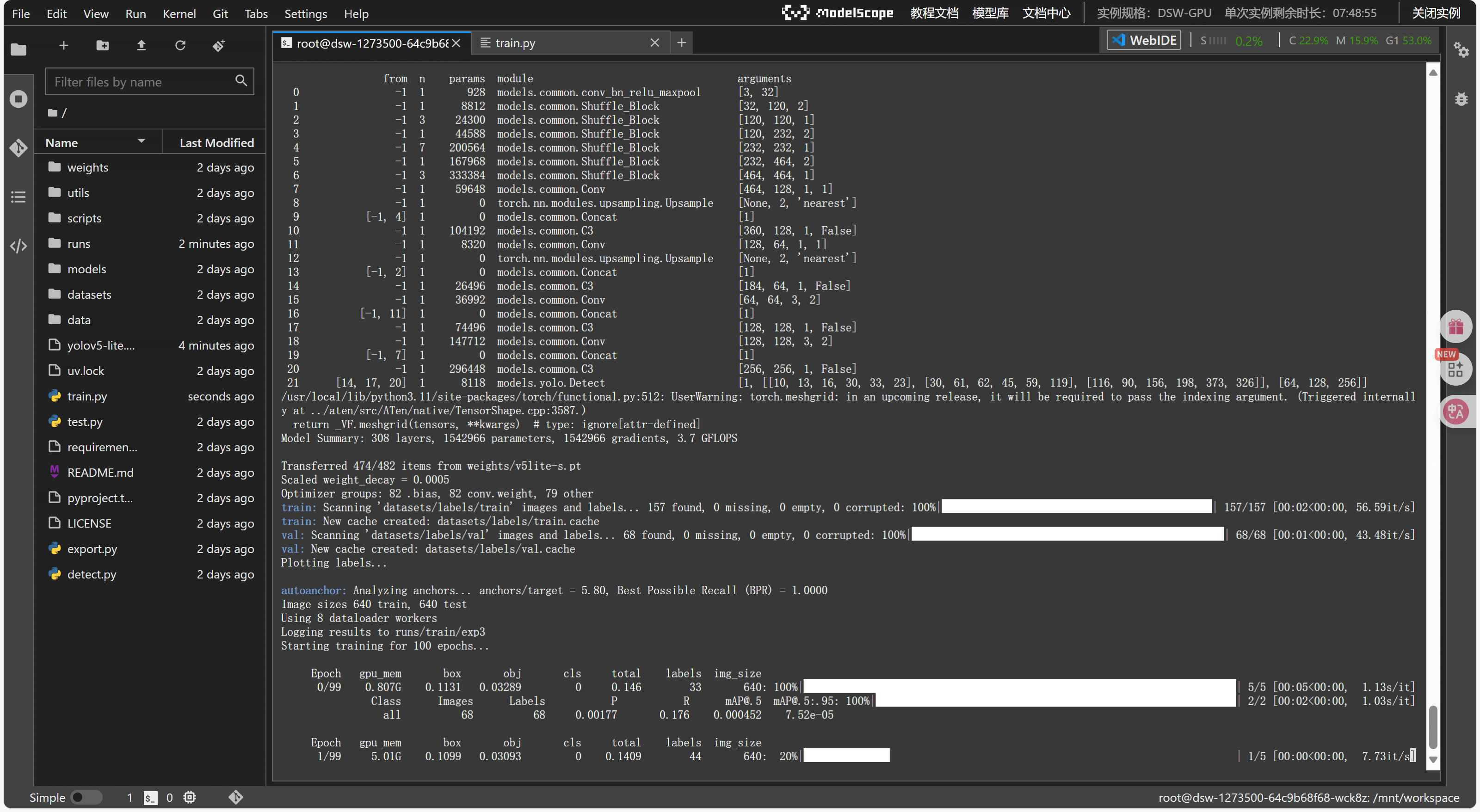
直接开始训练
python train.py
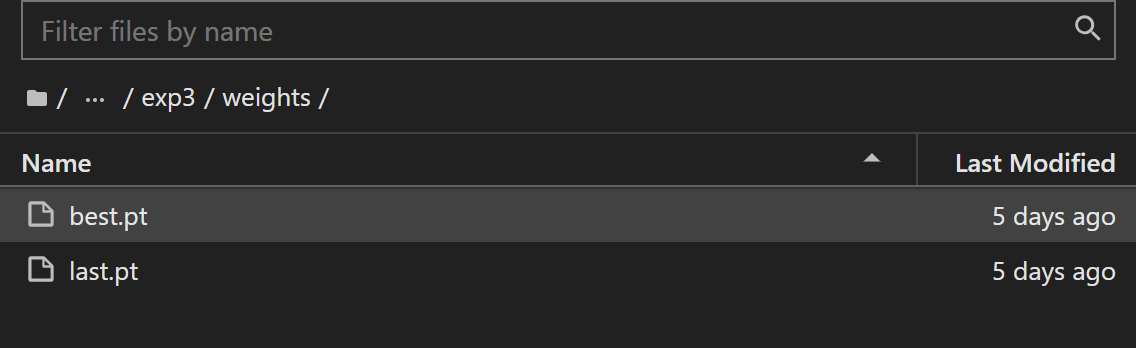
训练结束之后可以在./runs/train/exp/weights/文件夹下面可以找到我们的pt模型,best.pt 是在验证集上效果最好的一轮参数,last.pt是我们训练到最后的参数。最后我们将训练好的pt文件直接传到树莓派的YOLOv5-Lite/weights文件夹即可里面,再更改以下detect.py下的模型路径即可。
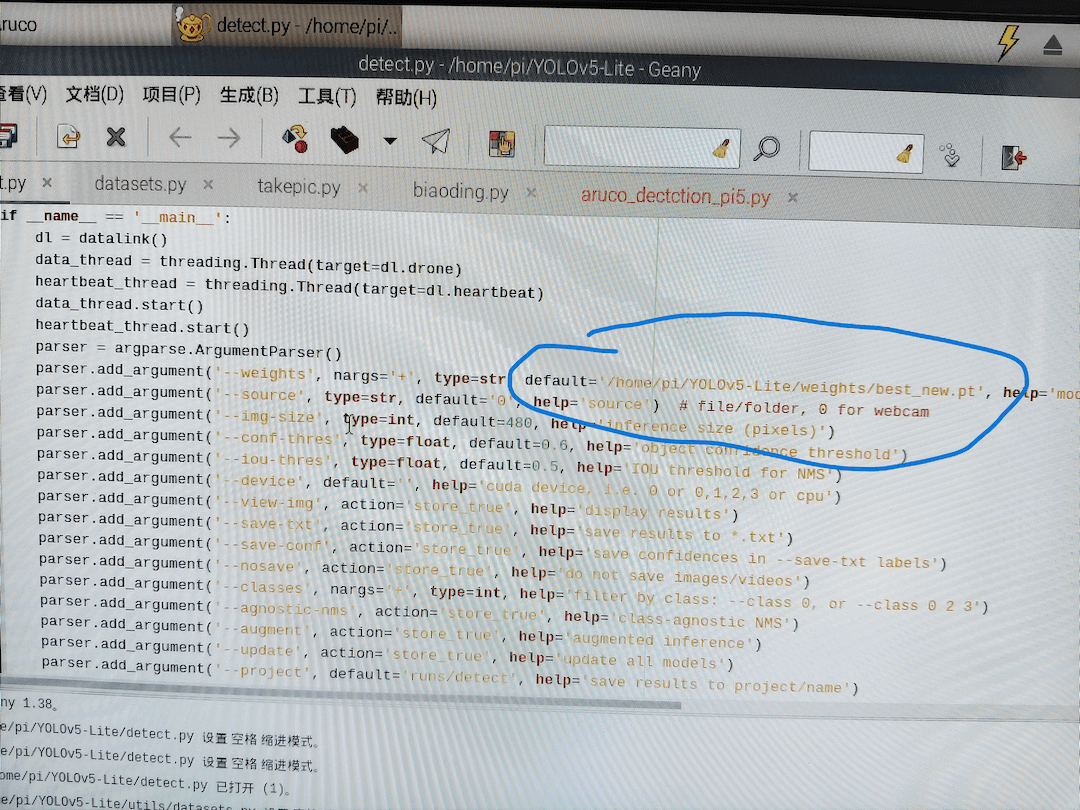
我们提供了YOLOv5-Lite(custom_model)文件包供您参考,内含识别无人机的模型
下面说明参数变更:
这是原程序
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='/home/pi/YOLOv5-Lite/weights/v5lite-s.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='0', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=256, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.4, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.5, help='IOU threshold for NMS')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
opt = parser.parse_args()
可能要更改的参数
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='/home/pi/YOLOv5-Lite/weights/best_new.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='0', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=480, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.6, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.5, help='IOU threshold for NMS')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
opt = parser.parse_args()
- weights: 权重文件,内含模型参数,就是我们训练出来的pt模型
- source: 识别数据的来源,是来自图片还是视频还是摄像头
- img-size: 输入图片尺寸,图片数据在输入神经网络的前一步会被进行缩放,这个参数越小,对于神经网络来说越好处理,识别的速率越高,但是识别的精度越低。
- conf-thres: 识别置信度阈值,当类别得分大于这个分数才会被识别。
- iou-thres: NMS 的交并比阈值,用于去除与高分检测框重叠度过高的冗余检测框
- view-img: 是否查看识别结果。
第二章 树莓派5识别追踪Aruco码
项目概述
本节教程将会教会你如何使用FanciSwarm树莓派5套件实现Aruco码的前视视角的识别追踪和俯视视角的识别降落。
文件总览
Aruco
├─ aruco_dectction_pi5.py
├─ biaoding.py
├─ calibration_data.npz
├─ datalink_serial.py
├─ mavcrc.py
├─ mavcrc.pyc
├─ mavlink.py
├─ mavlink.pyc
├─ takepic.py
└─ __pycache__
├─ datalink_serial.cpython-311.pyc
├─ mavcrc.cpython-311.pyc
└─ mavlink.cpython-311.pyc
相机标定参数的生成
实验平台:幻思创新FanciSwarm® 树莓派5 无人机
我们在使用aruco码检测程序的时候需要用到单目测距,因此需要提前获取相机标定参数
首先去网上下载标定专用棋盘格
https://github.com/opencv/opencv/blob/master/doc/pattern.png
{kind=link}
接着我们使用提供的takepic.py去进行图像采集,采集过程中要确保下面要点
- 尽量从不同的角度、不同的距离拍摄棋盘格。
- 每张照片中的棋盘格应尽量占据较大的画面区域。
- 确保所有棋盘格点都清晰可见并没有因反光等原因模糊不清。
将拍摄好的图片保存在images文件夹(需要自行创建)下,放到我们的文件包中。
然后我们打开biaoding.py文件,修改下面图片存放路径(第17行)
images = glob.glob('images/*.jpg')
运行biaoding.py文件得到calibration_data.npz参数文件
Aruco码识别
我们修改文件包中的aruco_detection_pi5.py文件中你保存的参数路径(第11行)
with np.load('/home/pi/Aruco/calibration_data.npz') as data:
camera_matrix = data['camera_matrix']
dist_coeffs = data['dist_coeffs']
修改开机自启动项
修改开机自启动项只需要修改/home/pi/.config/autostart下面的Desktop文件,将Exec更换为python /home/pi/Aruco/aruco_detection_pi5.py
[Desktop Entry]
Type=Application
Name=MyPythonScript
Exec=lxterminal --command "/bin/bash -c 'source /home/pi/YOLOv5-Lite/venv-yolo/bin/activate && /home/pi/Aruco/aruco_detection_pi5.py'"
前视视角的Aruco码识别追踪
前视视角安装的摄像头使用
文件包程序默认就是前视视角的识别追踪
前视视角更改为俯视视角Aruco码识别降落
俯视视角安装的摄像头使用
俯视视角只需要将set_pose函数更改为set_xy_pose如下所示
将
dl.set_pose(kp_x * dx_1, kp_y * dy_1, kp_alt * d_alt_1, kp_yaw * d_yaw)
更改为
dl.set_xy_pose(kp_alt * d_alt_1, kp_y * dy_1, 0)
第三章 树莓派5视频流传输
实验平台:使用幻思创新FanciSwarm® 树莓派5 无人机和个人PC的windows环境
文件总览
TcpNoDelay_transtream_PI5.py
TcpNoDelay_recvstream_PC.py
- detect.py 视频流传输替换文件
detect.py
环境配置
PC端环境配置:
python环境:3.10
安装opencv以及对应版本的numpy
pip install opencv-contrib-python==4.6.0.66
pip install numpy==1.24.0
配置静态ip
配置静态ip之后会导致无法访问公网,因此若还有访问公网的需要请在后面进行这一步
点击右上角wifi图标并选择Advanced Options->编辑连接
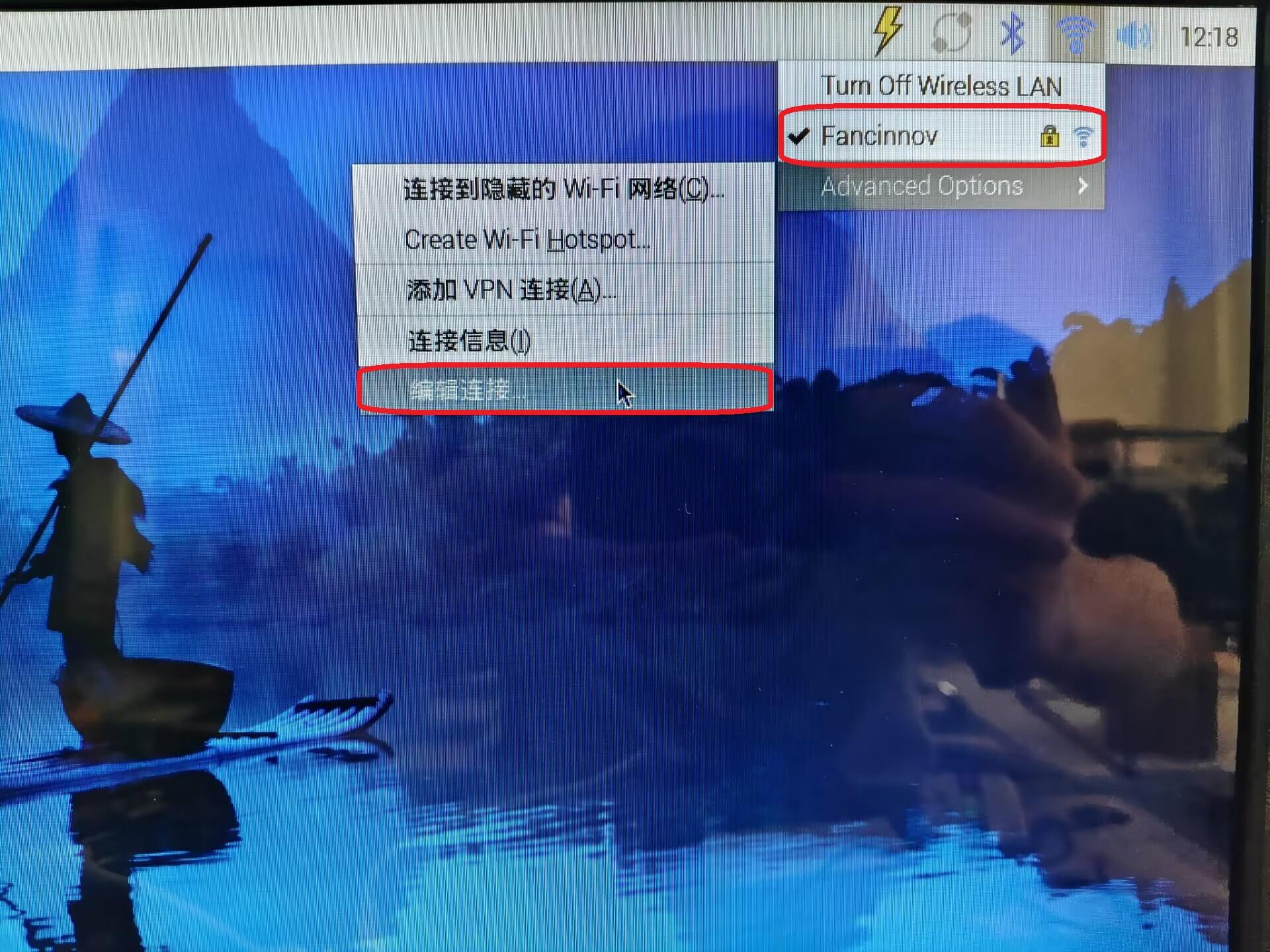
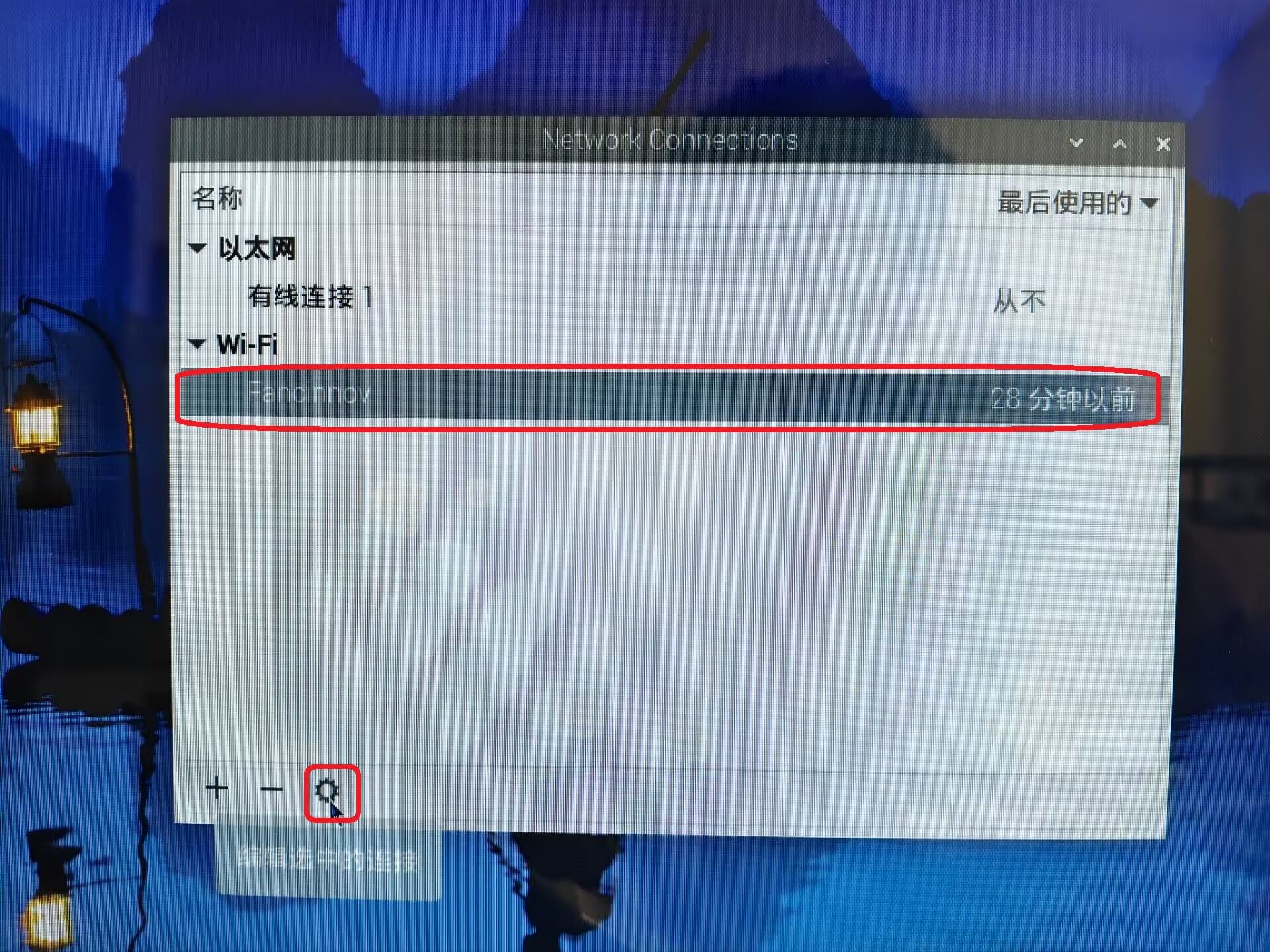
选择自己家路由器wifi并且点击设置图标
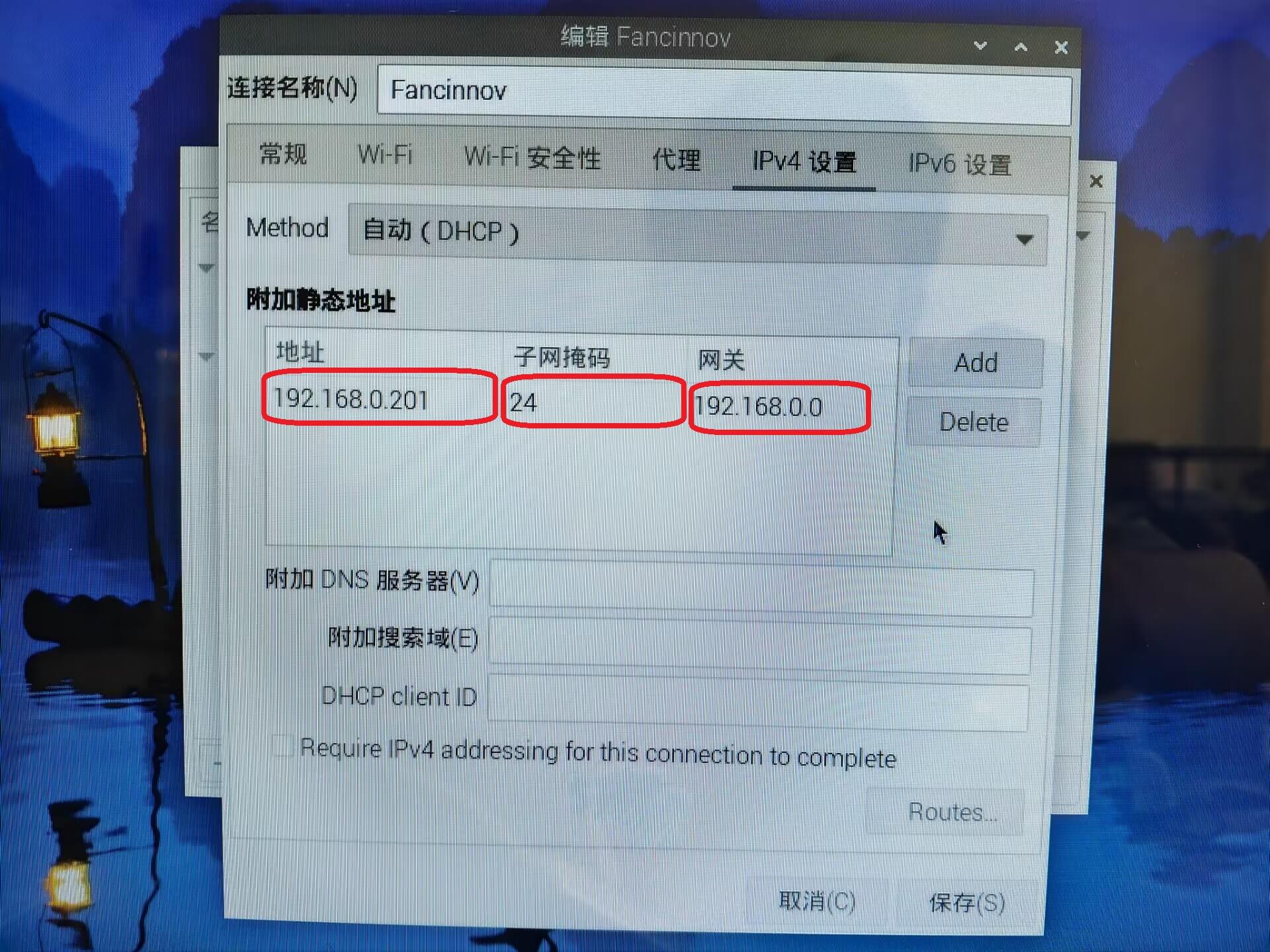
ipv4设置中附加静态地址,这个静态地址要根据路由器所支持网段来选择,图片中仅供参考
修改python文件配置
我们使用远程文件传输或者u盘将提供的TcpNoDelay_transtream_PI5.py文件放到/home/pi目录下面,我们依旧使用YOLOv5-Lite的虚拟环境
source /home/pi/YOLOv5-Lite/venv-yolo/bin/activate
直接启动脚本
python ./TcpNoDelay_transtream_PI5.py
运行结果就是等待客户端连接,然后我们在pc端运行我们提供的客户端脚本TcpNoDelay_recvstream_PC.py
等到树莓派端启动了脚本之后,直接启动脚本
python ./TcpNoDelay_recvstream_PC.py
效果如下所示
树莓派端
![]()
PC端
![]()
如何在yolo识别中增加视频流传输
实验平台:幻思创新FanciSwarm® 树莓派5 无人机
直接将本章文件总览里的detect.py替换原YOLOv5-Lite文件包下面的detect.py即可。
具体修改部分请看下面说明
增添内容均在YOLOv5-Lite/detect.py文件中
- 文件顶部引入外部库
import subprocess
import multiprocessing as mp
import threading
import queue
import socket
- 定义广播ip地址和端口号
TCP_IP = '0.0.0.0'
TCP_PORT = 5005
- 在
if __name__ == "__main__":上方引入视频流传输类
class TranstreamThread(threading.Thread):
def __init__(self, TCP_IP, TCP_PORT):
super().__init__()
self.TCP_IP = TCP_IP
self.TCP_PORT = TCP_PORT
self.sock = None
self.conn = None
self.addr = None
self.running = True
self.connected = False
self.queue = queue.Queue()
def run(self):
self.sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) # 允许端口重用
self.sock.bind((self.TCP_IP, self.TCP_PORT))
self.sock.listen(1)
print(f"服务器已启动,监听 {self.TCP_IP}:{self.TCP_PORT}")
while self.running:
print("等待客户端连接...")
try:
self.conn, self.addr = self.sock.accept() # 每次 accept 一个新的客户端
print(f"客户端已连接:{self.addr}")
self.connected = True
# 设置 TCP_NODELAY
self.conn.setsockopt(socket.IPPROTO_TCP, socket.TCP_NODELAY, 1)
# 处理当前客户端通信
while self.running and self.connected:
try:
frame = self.queue.get(timeout=1) # 等待图像帧
self._send_frame(frame)
except queue.Empty:
continue
except socket.error as e:
print(f"accept() 出错:{e}")
self.connected = False
continue
def _send_frame(self, frame):
try:
size_data = len(frame).to_bytes(4, 'big')
self.conn.sendall(size_data)
self.conn.sendall(frame)
except (socket.error, BrokenPipeError) as e:
print(f"客户端断开连接:{e}")
self.connected = False # 客户端断开后标记为未连接
self._close_connection()
def send_frame(self, frame):
if self.connected:
self.queue.put(frame)
return True
return False
def _close_connection(self):
if self.conn:
try:
self.conn.close()
except:
pass
self.conn = None
def stop(self):
self.running = False
self.connected = False
self._close_connection()
if self.sock:
self.sock.close()
- 由于监听tcp连接会导致线程阻塞,所以我们需要使用另一个线程来进行监听任务,增添
thread2监听线程
if __name__ == '__main__':
dl = datalink()
thread2 = TranstreamThread(TCP_IP, TCP_PORT) # 增加的监听线程
data_thread = threading.Thread(target=dl.drone)
heartbeat_thread = threading.Thread(target=dl.heartbeat)
thread2.start() # 启动监听线程
data_thread.start()
heartbeat_thread.start()
parser = argparse.ArgumentParser()
- 在imshow()函数后面进行视频流的编码并发送。
# Stream results {#stream-results }
if view_img:
cv2.imshow(str(p), im0)
encode_param = [int(cv2.IMWRITE_JPEG_QUALITY), 70] # 增添
result, img_encoded = cv2.imencode('.jpg', im0, encode_param) # 增添
data = img_encoded.tobytes() # 增添
thread2.send_frame(data) # 增添
cv2.waitKey(1) # 1 millisecond